在现代高性能计算(HPC)和人工智能(AI)应用中,GPU已成为加速计算的核心组件。随着多GPU系统和大规模集群的普及,GPU之间的高效通信成为系统性能的关键瓶颈。GPU通信技术中的GPU Direct RDMA(Remote Direct Memory Access)网络服务应运而生,它通过绕过CPU和系统内存,实现GPU与网络设备之间的直接数据交换,显著提升了通信效率和系统整体性能。
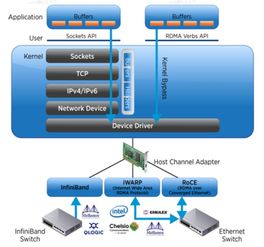
GPU Direct RDMA是NVIDIA推出的一项关键技术,属于GPU Direct技术家族的一部分。其核心思想是允许第三方设备(如InfiniBand或以太网适配器)通过RDMA协议直接访问GPU内存,而无需经过主机CPU和系统内存的拷贝。这种直接通信机制消除了不必要的数据移动,降低了通信延迟,并释放了CPU资源,使其能够专注于计算任务。
GPU Direct RDMA的工作原理基于以下几个关键组件:它利用NVIDIA GPUDirect技术框架,在GPU驱动和网络驱动之间建立直接通信路径;通过支持RDMA的网络适配器(如Mellanox InfiniBand网卡),数据可以直接从源GPU内存传输到目标GPU内存;操作系统和应用程序通过API(如NVIDIA Collective Communications Library, NCCL)管理这些传输过程,确保数据的一致性和正确性。
在实际应用中,GPU Direct RDMA服务为分布式训练和科学模拟带来了巨大优势。例如,在深度学习训练中,多个GPU节点需要频繁交换梯度数据,传统方式需经过CPU内存中转,导致高延迟和带宽浪费。而GPU Direct RDMA允许梯度数据直接从GPU内存通过网络传输到其他节点的GPU内存,减少了通信时间,加速了训练过程。测试表明,在使用InfiniBand网络时,GPU Direct RDMA可将通信延迟降低高达30%,并有效利用网络带宽。
GPU Direct RDMA的部署也面临一些挑战。它需要兼容的硬件支持,包括特定型号的NVIDIA GPU和支持RDMA的网络设备;软件配置较为复杂,需确保驱动、库和应用程序的兼容性;在多租户环境中,直接内存访问可能引发安全问题,需要额外的隔离机制。
随着AI和HPC需求的持续增长,GPU Direct RDMA技术将进一步优化,例如通过集成更先进的网络协议(如NVLink over Fabric)和支持更广泛的硬件平台。同时,开源社区和厂商正在推动标准化,以简化部署并提升可访问性。
GPU Direct RDMA网络服务作为GPU通信技术的重要进展,通过实现高效的直接数据交换,为大规模并行计算提供了坚实基础。它不仅提升了应用性能,还推动了整个计算生态的创新,是未来高性能系统不可或缺的一部分。









